
本記事は米国向けに公開されている開発元のブログ記事をベースとし、日本国内のUnderstand 7.0 APIの活用をご検討されているお客様向けに加筆・修正を加えたものとなります。
前回の記事はこちらをご確認ください。
※一部の記事の内容ではUnderstand 6.5が使用されていますが、基本的な機能はUnderstand 7.0でも同様にご利用いただけます。
チュートリアル目次
第1回:Understand APIチュートリアル1:Python API入門
第2回:Understand APIチュートリアル2:最初のAPIスクリプトの作成
第3回:Understand APIチュートリアル3:Entity、References、Kind Filterとは
第4回:Understand APIチュートリアル4:字句解析(Lexer、Lexemeとは)
第5回:Understand APIチュートリアル5:グラフ
第6回:Understand APIチュートリアル6:インタラクティブレポート
字句解析器LexerとLexeme
多くのAPIスクリプトやプログラムは、 Understandデータベースに保存されているエンティティや参照を利用しますが、ファイル自体のテキストまで掘り下げて解析する必要がある場合もあります。Understandでは、 lexer()関数とlexemeクラスを使ってこれを実現できます。
Lexer(レクサー) – 語彙素のストリームです。
Lexeme(語彙素) – パーサーにとって意味を持つテキストの塊です。
例:文字列、コメント、変数
Understandを使用すると、Lexeme(語彙素)のストリームを調べて、それぞれのテキスト、それに関連付けられているエンティティまたは参照、それが持つトークン (句読点、コメント、プリプロセッサなど)、またはそれがどの行にあるかなどを照会できます。
【補足】
APIレベルで使い方を補足しますと、ストリームであるlexerを使って、lexer.first()やlexer.lexeme(行番号、列番号(=何文字目か))でlexemeオブジェクト(語彙素オブジェクト)を取得します。
また、lexer.lexemes() でlexemeオブジェクトを配列で取得することができます。
それぞれのlexeme オブジェクトは lexeme.token() でそのトークンの種類を、lexeme.text() でそのテキストを、lexeme.ent() で関連するエンティティを取得することができます。lexeme.line_begin()で行番号を、lexeme.column_begin()列の位置を取得することもできます。
たとえば、次のような単純な行がある場合、
int a=5;//radiusそのLexeme(語彙素)には次の情報が含まれます。
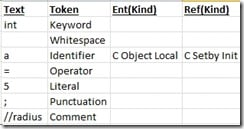
使用例(lexerとlexeme)
以下はlexer()関数とlexemeクラスの使用例です。
file.lexer()において、すべての非アクティブなコードとコメントを削除し、マクロを展開したファイルのテキストをリストとして返しています。
※下記のサンプル内で使用されているEnt.lexer()関数、Lexemeクラスの仕様につきましてはUnderstandの[ヘルプ]-[Python APIヘルプ]よりご確認いただけます。
import understand
db = understand.open("C:/sample project/sample_project.und")
def fileCleanText(file):
returnString = ""
# Open the file lexer with macros expanded and inactive code removed
for lexeme in file.lexer(lookup_ents = False, tabstop = 8, show_inactive = False, expand_macros = True):
if(lexeme.token() != "Comment"):
# Go through lexemes in the file and append
# the text of non-comments to returnText
returnString += lexeme.text()
return returnString
# Search for the first file named ‘test’ and print
# the file name and the cleaned text
file = db.lookup(".test.","file")[0]
print (file.longname())
print(fileCleanText(file))次回はAPIを利用したグラフ出力について解説いたします。

