はじめに
前回、こちらのブログ記事にて、Sturtevantの構造複雑度を使用したメトリクスの活用という題目のもと、LattixのメトリクスレポートをPythonのスクリプトを使って、Jupyter NoteBookで加工しやすい表にするまでの手順を紹介しました。[第1回記事はこちらから]
今回は、第2回としまして、VFI・VFO(Visibility Fun-in/out)を使った閾値分けについて紹介します。
使用するメトリクスの絞り込み
今回、使用するメトリクスは、アーキテクチャメトリクス・システムメトリクスです。
アーキテクチャメトリクスからは、影響度平均・平均累積依存度を使用します。
また、さらに効果的に分析するために、Sturtevantの構造複雑度4分類を行う上では必須のメトリクスではありませんが、追加項目としてシステムメトリクスの”Cyclomatic Complexity”を使用します。
※システムメトリクスの”Cyclomatic Complexity”では、ファイル粒度のメトリクスとして、ファイル内の関数のCyclomatic複雑度の最大値が出力されます
df_ltx_org=pd.merge(df_ltx_org_System,df_ltx_org_Architecture, on="サブシステム")# マージ後のデータ
df_ltx_orgまず、前回の記事で出力した表から、メトリクスが適切にマージされているかを確認します。
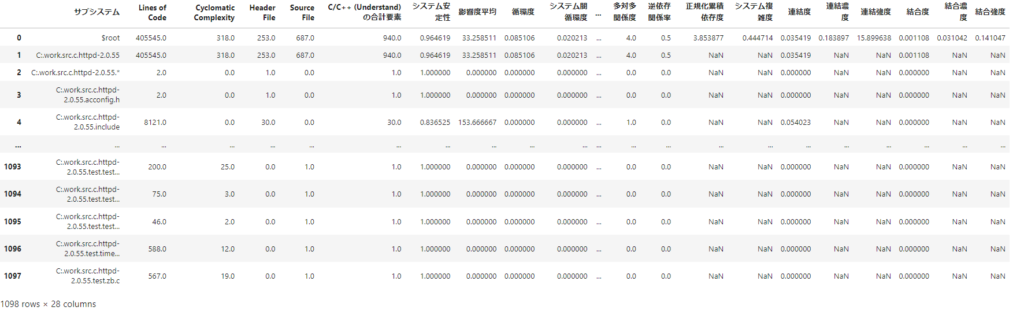
これは、アーキテクチャメトリクスやシステムメトリクスを1つの表にプロットしただけの状態です。
これらの中から、今回使用するものだけに絞り込みを行います。
# 使用するメトリクスの指定
metrics = ["影響度平均","平均累積依存度","Cyclomatic Complexity"]
# ファイル要素のみ抽出(サブシステムに対するメトリクスデータを除外)
if "C/C++ (Understand) の合計要素" in df_ltx_org.columns :
default_culumn = ["サブシステム","Header File","Source File","C/C++ (Understand) の合計要素"]
culumn_use = default_culumn + metrics
df_ltx=df_ltx_org.loc[:,culumn_use]
df_ltx_file=df_ltx[df_ltx["C/C++ (Understand) の合計要素"]==1.0]
elif ".NET の合計要素" in df_ltx_org.columns :
default_culumn = ["サブシステム",".NET の合計要素"]
culumn_use = default_culumn + metrics
df_ltx=df_ltx_org.loc[:,culumn_use]
df_ltx_file=df_ltx[df_ltx[".NET の合計要素"]==1.0]
elif "Java の合計要素" in df_ltx_org.columns :
default_culumn = ["サブシステム","Java の合計要素"]
culumn_use = default_culumn + metrics
df_ltx=df_ltx_org.loc[:,culumn_use]
df_ltx_file=df_ltx[df_ltx["Java の合計要素"]==1.0]これによって、使用するメトリクスのみを絞り込むことができました。
この要素を使ってVFI・VFOを計測していきます。
VFI・VFOとは?
計測に入る前に、VFI・VFOとは何を指しているのでしょうか。こちらで解説していきます。
まず、VFI・VFO(Visibility Fan-in/out)とは、間接依存を含むFan-in/outのことを指します。
最初に、以下の図1のように、File AからFile Bに対しての直接関係のある依存関係を明らかにします。
このとき、抽出した依存関係から、右のようなネットワーク表現を構成します。
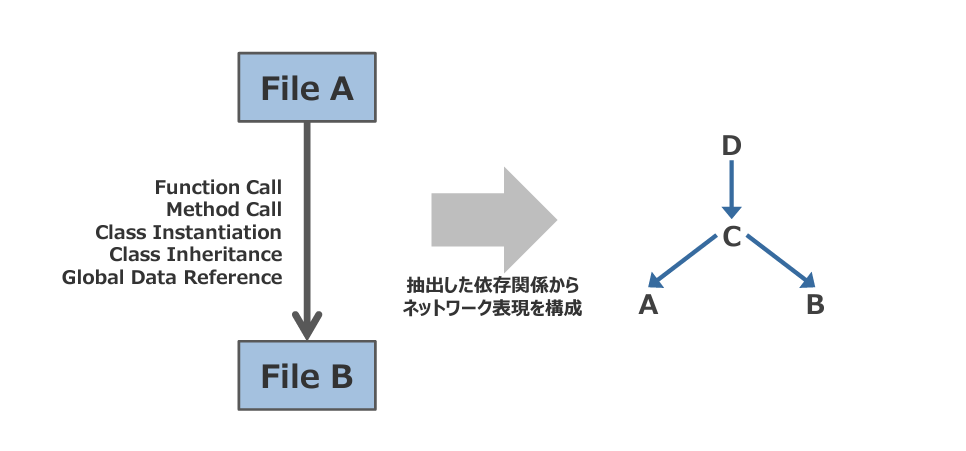
次に、間接的な依存要素を加えて計測します。File AからFile B内の依存関係のなかで、要素 Dは要素 Cを介して、要素 Aと要素 Bに間接的に依存関係があるため、以下の図2のように直接依存しているFun-in/outの要素に加えて、間接的な依存要素を計測対象に加えます。
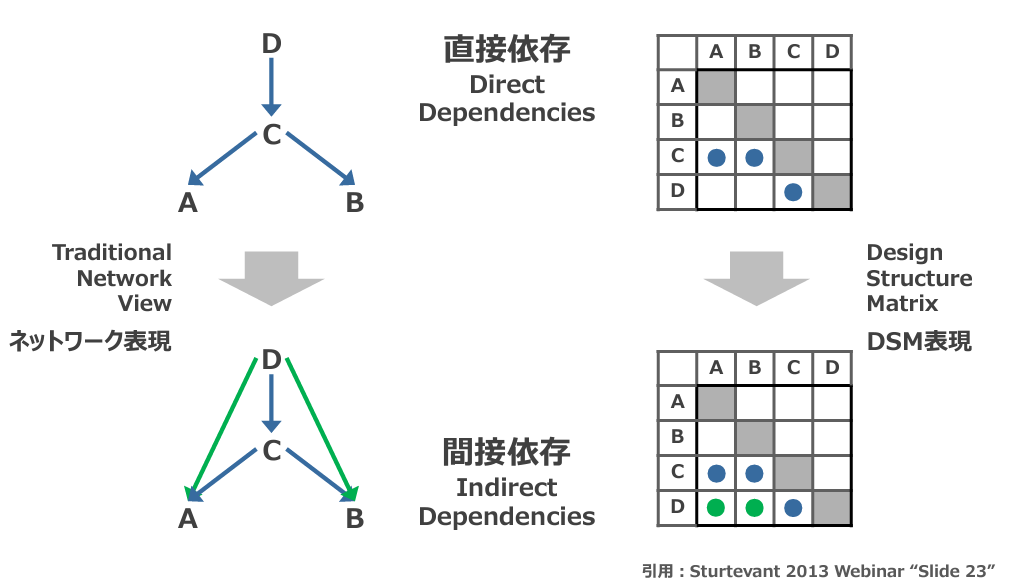
これが、VFI・VFOになります。
VFI・VFOの計測と閾値分け
VFI/VFOを計測していきます。要素自体は前項で抽出しているため、影響度平均の値と、平均累積依存度の値を使って、以下のように計算をしていきます。
# VFI,VFOの計算(VFI = 影響度平均+1, VFO = 平均累積依存度)
df_ltx_file.loc[:,"VFI"]=pd.DataFrame(df_ltx_file["影響度平均"].copy(deep=True)+1)
df_ltx_file.loc[:,"VFO"]=pd.DataFrame(df_ltx_file["平均累積依存度"].copy(deep=True))
df_ltx_file.loc[:,"SQRT(VFI*VFO)"]=pd.DataFrame(np.sqrt(df_ltx_file["VFI"].copy(deep=True)*df_ltx_file["VFO"].copy(deep=True)))ここから得ることができた値から閾値を設定します。
VFI・VFOの閾値は、それぞれの最大の値の半分で設定をします。(Sturtvantの論文より)
- (VFI,VFO)が各閾値に対して、領域を定義します。
・(小,小)=”0_periferal”
・(大,小)=”1_utility”
・(小,大)=”2_control”
・(大,大)=”3_core” - Cyclomatic Complexityは以下のように範囲を指定します。(Sturtevantの論文より)
・1-10:1_low,
・11-20:2_medium
・21-50:3_high
・51-:4_untestable
・0の場合は0_nothing
※関数が含まれていないファイルは基本的にはCyclomatic Complexityが0になります。
# VFI,VFOの閾値を計算(ここでは最大値の半分と定義)
threshold_VFI = df_ltx_file["VFI"].max()/2.0
threshold_VFO = df_ltx_file["VFO"].max()/2.0
groupname = {0:"0_periferal",1:"1_utility",2:"2_control",3:"3_core"}
cyc_groupname = {0:"0_nothing", 1:"1_low", 2:"2_medium", 3:"3_high", 4:"4_untestable"}
def judge_vfio(df_input):
judgeVFI = df_input["VFI"].apply(lambda x: 1 if (x>threshold_VFI) else 0)
judgeVFO = df_input["VFO"].apply(lambda x: 2 if (x>threshold_VFO) else 0)
return judgeVFI+judgeVFO
def judge_cyc(df_input):
low_min=1
medium_min = 11
high_min = 21
untestable_min = 51
low = df_input["Cyclomatic Complexity"].apply(lambda x: 1 if (x>=low_min) else 0)
medium = df_input["Cyclomatic Complexity"].apply(lambda x: 1 if (x>=medium_min) else 0)
high = df_input["Cyclomatic Complexity"].apply(lambda x: 1 if (x>=high_min) else 0)
untestable = df_input["Cyclomatic Complexity"].apply(lambda x: 1 if (x>=untestable_min) else 0)
return low+medium+high+untestable
def get_groupName(df_input):
return df_input["group"].apply(lambda x: groupname[x])
def get_cycgroupName(df_input):
return df_input["cyc_group"].apply(lambda x: cyc_groupname[x])
df_ltx_file.loc[:,"group"]=judge_vfio(df_ltx_file)
df_ltx_file.loc[:,"groupName"]=get_groupName(df_ltx_file)
df_ltx_file.loc[:,"cyc_group"]=judge_cyc(df_ltx_file)
df_ltx_file.loc[:,"cyc_groupName"]=get_cycgroupName(df_ltx_file)そして、正しく閾値分けができているか、以下のコードで確認します。
df_ltx_fileその結果、以下のような表がプロットでき、閾値分けができていることが分かります。
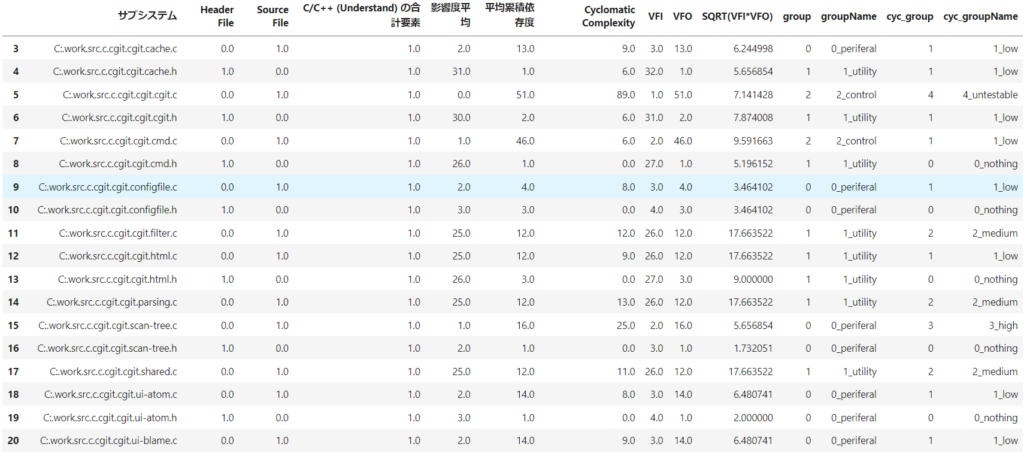
※実際のプロジェクトに適用した場合、1ファイルだけVFI、VFOの片方の値が特異的に高い場合は、閾値が高くなり、
Coreに該当する要素が出ないことが予想されます。 この場合には、閾値を「最大値の”半分”」ではなく、
「最大値の”1/3″や”1/4″」にする、もしくは「VFI, VFOのプロジェクト内偏差値が60以上」とする等、プロジェクトに合わせて
閾値を変更されることをお勧めいたします。
また、閾値分けに使われた閾値は以下のコードで出力することができます。
print("閾値:VFO:"+str(threshold_VFO)+" "+"VFI:"+str(threshold_VFI))閾値:VFO:25.5 VFI:16.0
最後に
今回はここまでになります。
次回の最終回では、この閾値分けをしたものを分析しやすくプロットする手順を紹介します。
今回も最後まで読んでくださりありがとうございました。

